Bluefog Timeline¶
Bluefog timeline is used to record all activities occurred during your distributed training process. With Bluefog timeline, you can understand the performance of your training algorithm, indentify the bottleneck, and then improve it.
The development of Bluefog timeline is based on the Horovod timeline. Similar to Horovod,
Bluefog timeline clearly visualizes the start and end of all communication stages between
agents such as allreduce, broadcast, neighbor_allreduce, win_put,
win_accumulate and many others. Some of these communication primitives are exclusive
to Bluefog.
An enhanced feature of Bluefog timeline is to visualize the computation states of each
agent such as forward propogation and backward propogation. The visualization of both
communication and computation will help a better understanding of your training algorithm.
For example, Bluefog timeline will tell how your computation is in parallel with the
communication.
Usage¶
To record a Bluefog timeline, set --timeline-filename command line argument to the
location of the timeline file to be created. This will generate a timeline record file
for each agent. For example, the following command
$ bfrun -np 4 --timeline-filename /path/to/timeline_filename python example.py
will generate four timeline files: timeline_filename0.json, timeline_filename1.json,
timeline_filename2.json, and timeline_filename3.json, and each json file is for
a different agent. You can then load the timeline file into the
chrome://tracing facility of the Chrome browser. If the operation --timeline-filename
is not set, the timeline function will be deactivated by default.
Example I: Logistic regression with neighbor_allreduce¶
In the first example, we show the timeline when running decentralized SGD for
logistic regression, see the figure below. In this example, each rank is connected
via an undirected exponential-2 topology. We exploit the
primitive neighbor_allreduce to perform the neighbor averaging.
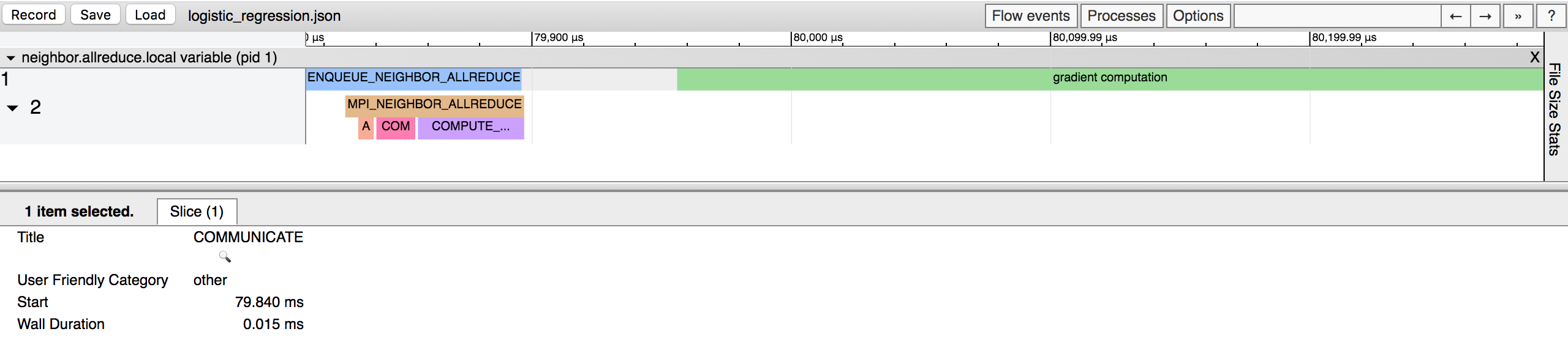
There are two active threads in the timeline: thread 1 that is mainly for gradient
computation and thread 2 for communication. There is a phase MPI_NEIGHBOR_ALLREDUCE
in thread 2 when neighbor allreduce actually happens. It is further divided into multiple
sub-phases:
ALLOCATE_OUTPUT: indicates the time taken to allocate the temporary memory for neighbor’s tensor.
COMMUNICATEindicates the time taken to perform the actual communication operation.
COMPUTE_AVERAGEindicates the time taken to compuate the average of variables received from neighbors. It is basically a reduce operation.
Another notable feature of this neighbor_allreduce timeline is that threads 1 and 2 are synchronized.
Each time when thread 1 enqueues a task for thread 2 to conduct communication, it will be blocked until
thread 2 finish communication. As a result, it is observed that the end of opeartion ENQUEUE_NEIGHBOR_ALLREDUCE
in thread 1 aligns with the end of opeartion MPI_NEIGHBOR_ALLREDUCE in thread 2.
Example II: Logistic regression with win_accumulate¶
In this example, we show the timeline when running gradient tracking (another well-known decentralized
algorithm) for logistic regression. Different from Example I, we employ the one-sided communication
primitives win_accumulate to exchange information between neighboring ranks.
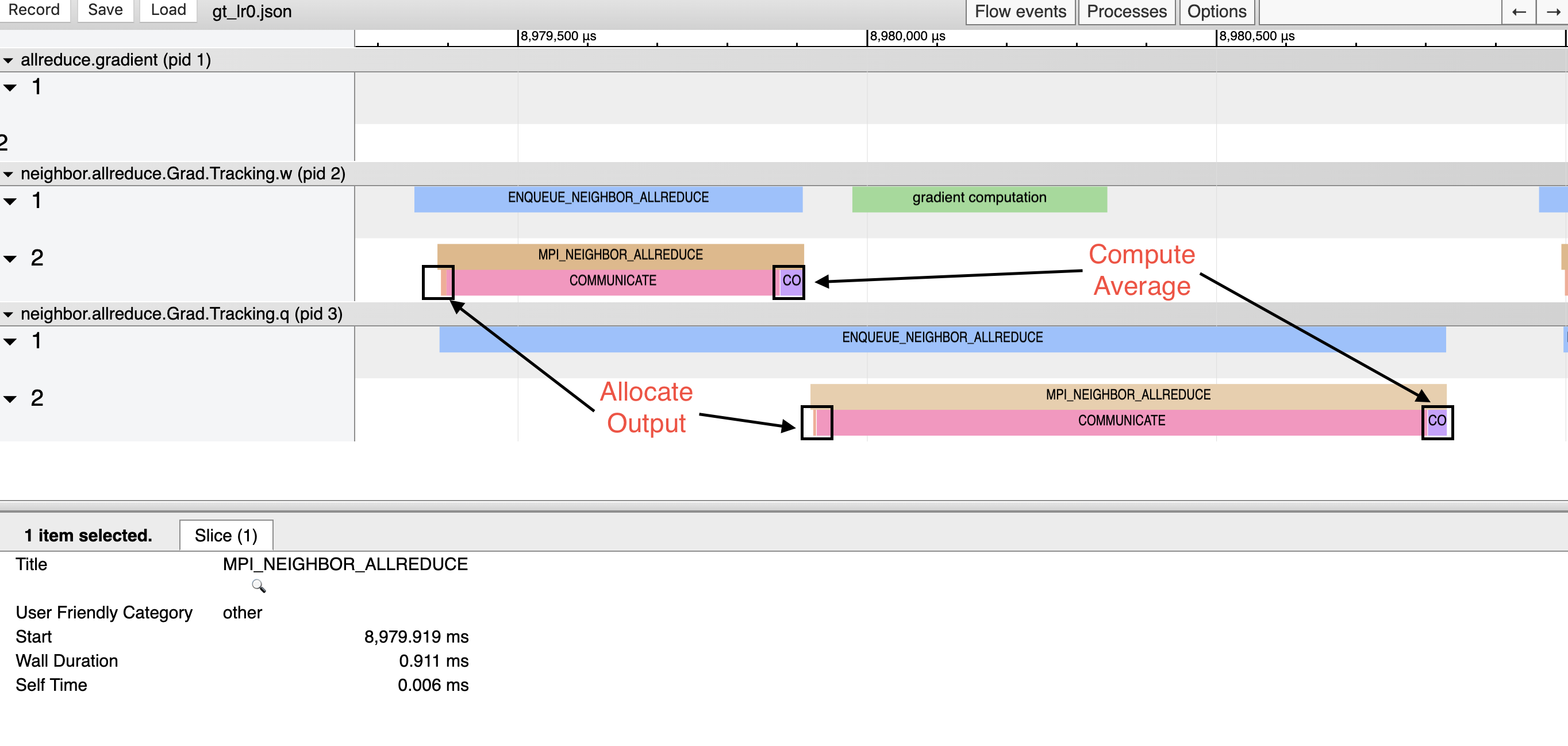
Different from Example I, it is observed that the computation and the communication were running independently. In the above figure, the gradient computation for variable w (pid 2) is overlapping with the communication of the variable q (pid 3). In other words, the one-sided communication primitive enables nonblocking operation and will significantly improve the training efficiency in real practice.
Example III: Resnet training with one-sided communication¶
In this example, we show the timeline for a real experiment when decentralized SGD is used to
train Resnet with CIFAR10 dataset. We exploit the one-sided communicaton primitive win_put
to exchange information between ranks.
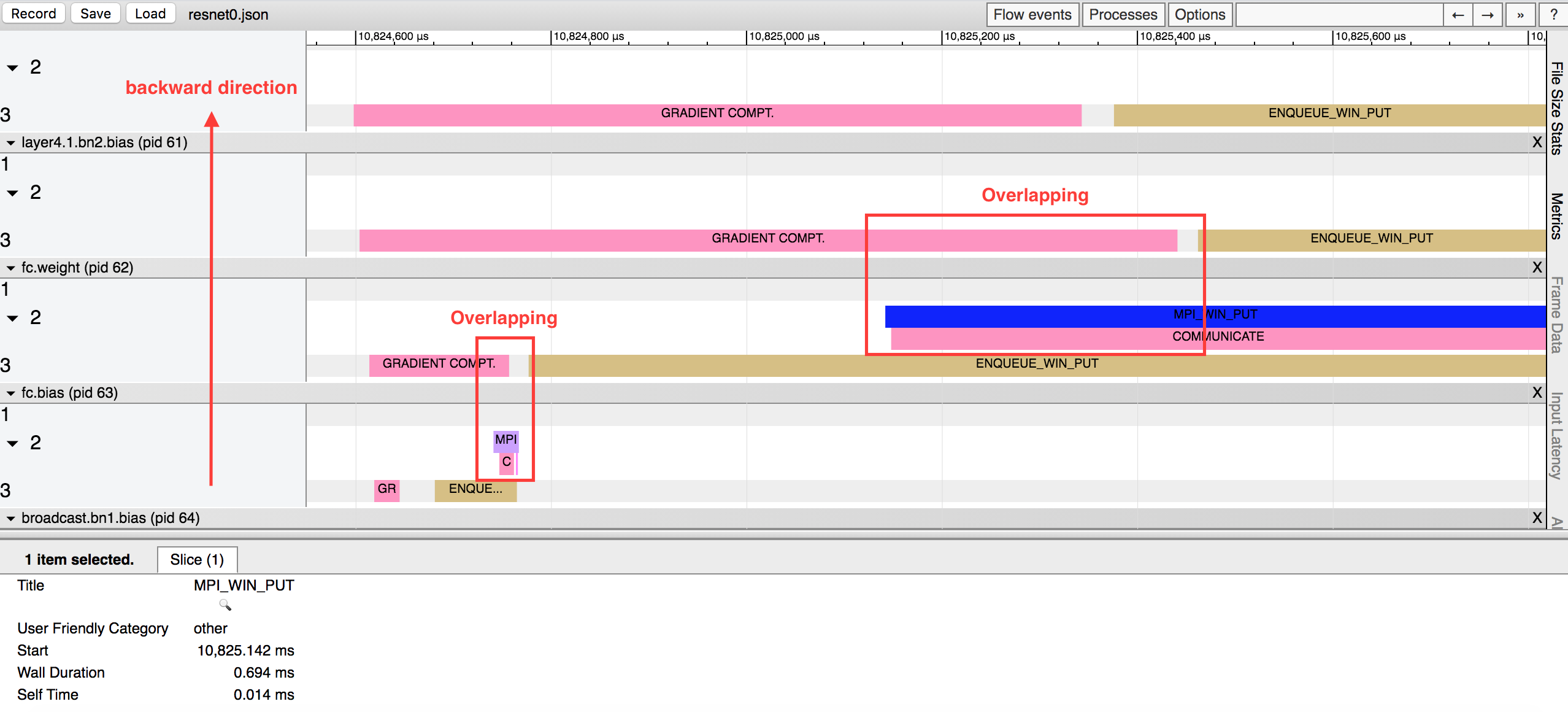
In the above figure, the left-side arrow indicates the layers in the backward direction. For example, pid 63 indicates the bias of the fully connected layer, pid 62 indicates the weigt matrix of the fully connected layer, and pid 61 indicates the bias of the batch normalization layer.
With the backpropagation algorithm, the back layers will finish the gradient computation earlier than front layers. To increase the efficiency, there is no need to wait to communicate until the full gradient is computed (i.e., the whole backpropagation is finished). Instead, BlueFog enables communication layer by layer and overlaps the communication of the back layers with the gradient computation of the front layers.
As illustrated in the above figure, the communication of the bias in the fully-connected layer (i.e. pid 63) overlaps with the gradient computation of the wieght in the fully-connected layer (i.e., pid 62). Similarly, communication of the wieght in the fully-connected layer (i.e., pid 62) overlaps with the gradient computation of the bias in the batch normalization layer (i.e., pid 61).