Torch Module (API Reference)¶
All APIs can be roughly categorized into 5 classes:
- Bluefog Basic Operations:
init, shutdown,
size, local_size, rank, local_rank, is_homogeneous
load_topology, set_topology, in_neighbor_ranks, out_neighbor_ranks
- High-level Optimizer Wrappers:
DistributedGradientAllreduceOptimizer
DistributedAllreduceOptimizer
DistributedNeighborAllreduceOptimizer
DistributedHierarchicalNeighborAllreduceOptimizer
DistributedWinPutOptimizer
- Low-level Synchronous Communication Operations:
allreduce, allreduce_nonblocking, allreduce_, allreduce_nonblocking_
allgather, allgather_nonblocking
broadcast, broadcast_nonblocking, broadcast_, broadcast_nonblocking_
neighbor_allgather, neighbor_allgather_nonblocking
neighbor_allreduce, neighbor_allreduce_nonblocking
hierarchical_neighbor_allreduce, hierarchical_neighbor_allreduce_nonblocking
poll, synchronize, barrier
- Low-level Asynchronous Communication Operations:
win_create, win_free, win_update, win_update_then_collect
win_put_nonblocking, win_put
win_get_nonblocking, win_get
win_accumulate_nonblocking, win_accumulate
win_wait, win_poll, win_mutex
- Other miscellaneous and utility functions:
broadcast_optimizer_state, broadcast_parameters, allreduce_parameters
timeline_start_activity, timeline_end_activity
nccl_built, mpi_threads_supported, unified_mpi_window_model_supported
-
class
bluefog.torch.CommunicationType(value)¶ An enumeration.
-
neighbor_allreduce= 'neighbor.allreduce'¶
-
hierarchical_neighbor_allreduce= 'hierarchical.neighbor.allreduce'¶
-
allreduce= 'allreduce'¶
-
empty= 'empty'¶
-
-
bluefog.torch.DistributedAdaptThenCombineOptimizer(optimizer, model, communication_type=<CommunicationType.neighbor_allreduce: 'neighbor.allreduce'>, num_steps_per_communication=1)¶ An distributed optimizer that wraps another torch.optim.Optimizer. The communication is applied on the parameters when backward propagation triggered and run the communication after parameter updated with gradient.
In order to maximize the overlapping between communication and computation, we override the step() function in standard optimizer provided by PyTorch. Currenly, we support SGD, ADAM, AdaDelta, RMSProp, AdaGrad. If you don’t use these, you need to register your own step function to the returned optimizer through
>>> opt.register_step_function(step_func)
where the signature should be func(self, parameter, gradient, parameter_group) -> None. Note, it has to be paramter-wise and parameter_group is the one that the standard torch.optimizer provided, which can store the auxuilary information or state of optimizer like learning_rate, weight_decay, etc.
Returned optimizer has three extra parameters self_weight, neighbor_weights and send_neighbors, neighbor_machine_weights and send_neighbor_machines to control the behavior of hierarchical neighbor allreduce. Changing the values of these knobs to achieve dynamic topologies.
- Parameters
optimizer – Optimizer to use for computing gradients and applying updates.
model – The model or a list of models you want to train with.
communication_type – A enum type to determine use neighbor_allreduce, or allreduce, or hierarchical_neighbor_allreduce, or empty function as communcaiton behavior. Empty function just means no communication.
num_steps_per_communication – Number of expected backward function calls before each communication. This allows local model parameter updates per num_steps_per_communication before reducing them over distributed computation resources.
Example for two scenarios to use num_steps_per_communication:
- Scenario 1) Local accumulation of gradient without update model.
(Used in large batch size or large model cases)
>>> opt = bf.DistributedAdaptWithCombineOptimizer(optimizer, model, >>> communication_type=CommunicationType.neighbor_allreduce, >>> num_steps_per_communication=J) >>> opt.zero_grad() >>> for j in range(J): >>> output = model(data_batch_i) >>> loss = ... >>> loss.backward() >>> opt.step() # Allreducing happens here
Scenario 2) Local updating the model. (Used in case that decreasing the communication).
>>> opt = bf.DistributedAdaptWithCombineOptimizer(optimizer, model, >>> communication_type=CommunicationType.neighbor_allreduce, >>> num_steps_per_communication=J) >>> for j in range(J): >>> output = model(data_batch_i) >>> loss = ... >>> opt.zero_grad() >>> loss.backward() >>> opt.step() # Allreducing happens at the last iteration
-
bluefog.torch.DistributedAdaptWithCombineOptimizer(optimizer, model, communication_type=<CommunicationType.neighbor_allreduce: 'neighbor.allreduce'>, num_steps_per_communication=1)¶ An distributed optimizer that wraps another torch.optim.Optimizer. The communication is applied on the parameters when forward propagation triggered. Hence, communication is overlapped with both forward and backward phase. Unlike AdaptThenCombine, this dist-optimizer do not need to register customized step function.
Returned optimizer has three extra parameters self_weight, neighbor_weights and send_neighbors, neighbor_machine_weights and send_neighbor_machines to control the behavior of hierarchical neighbor allreduce. Changing the values of these knobs to achieve dynamic topologies.
- Parameters
optimizer – Optimizer to use for computing gradients and applying updates.
model – The model or a list of models you want to train with.
communication_type – A enum type to determine use neighbor_allreduce, or allreduce, or hierarchical_neighbor_allreduce, or empty function as communcaiton behavior. Empty function just means no communication.
num_steps_per_communication – Number of expected backward function calls before each communication. This allows local model parameter updates per num_steps_per_communication before reducing them over distributed computation resources.
Example for two scenarios to use num_steps_per_communication:
- Scenario 1) Local accumulation of gradient without update model.
(Used in large batch size or large model cases)
>>> opt = bf.DistributedAdaptWithCombineOptimizer(optimizer, model, >>> communication_type=CommunicationType.neighbor_allreduce, >>> num_steps_per_communication=J) >>> opt.zero_grad() >>> for j in range(J): >>> output = model(data_batch_i) >>> loss = ... >>> loss.backward() >>> opt.step() # Allreducing happens here
Scenario 2) Local updating the model. (Used in case that decreasing the communication).
>>> opt = bf.DistributedAdaptWithCombineOptimizer(optimizer, model, >>> communication_type=CommunicationType.neighbor_allreduce, >>> num_steps_per_communication=J) >>> for j in range(J): >>> output = model(data_batch_i) >>> loss = ... >>> opt.zero_grad() >>> loss.backward() >>> opt.step() # Allreducing happens at the last iteration
-
bluefog.torch.DistributedGradientAllreduceOptimizer(optimizer, model, num_steps_per_communication=1)¶ An distributed optimizer that wraps another torch.optim.Optimizer through allreduce ops. The communication happens when backward propagation happens, which is the same as Horovod. In addition, allreduce is applied on gradient instead of parameters.
- Parameters
optimizer – Optimizer to use for computing gradients and applying updates.
model – The model or a list of models you want to train with.
num_steps_per_communication – Number of expected backward function calls before each communication. This allows local model parameter updates per num_steps_per_communication before reducing them over distributed computation resources.
Example for two scenarios to use num_steps_per_communication:
- Scenario 1) Local accumulation of gradient without update model.
(Used in large batch size or large model cases)
>>> opt = bf.DistributedGradientAllreduceOptimizer(optimizer, model, >>> num_steps_per_communication=J) >>> opt.zero_grad() >>> for j in range(J): >>> output = model(data_batch_i) >>> loss = ... >>> loss.backward() >>> opt.step() # Allreducing happens here
Scenario 2) Local updating the model. (Used in case that decreasing the communication).
>>> opt = bf.DistributedGradientAllreduceOptimizer(optimizer, model, >>> num_steps_per_communication=J) >>> for j in range(J): >>> output = model(data_batch_i) >>> loss = ... >>> opt.zero_grad() >>> loss.backward() >>> opt.step() # Allreducing happens at the last iteration
-
bluefog.torch.DistributedWinPutOptimizer(optimizer, model, num_steps_per_communication=1, window_prefix=None)¶ An distributed optimizer that wraps another torch.optim.Optimizer with pull model average through bf.win_put ops.
- Parameters
optimizer – Optimizer to use for computing gradients and applying updates.
model – The model or a list of models you want to train with.
num_steps_per_communication – Number of expected model forward function calls before each communication. This allows local model parameter updates per num_steps_per_communication before reducing them over distributed computation resources.
window_prefix – A string to identify the unique DistributedWinPutOptimizer, which will be applied as the prefix for window name.
Returned optimizer has two extra parameters dst_weights and force_barrier. Set dst_weights dictionary as {rank: scaling} differently per iteration to achieve win_put over dynamic graph behavior. If force_barrier is True, a barrier function will put at step() to synchronous processes.
-
bluefog.torch.DistributedAllreduceOptimizer(optimizer, model, num_steps_per_communication=1)¶ An distributed optimizer that wraps another torch.optim.Optimizer through allreduce ops. The communication for allreduce is applied on the parameters when forward propagation happens.
Warning
This API will be deprecated in the future. Use
DistributedAdaptWithCombineOptimizerinstead.
-
bluefog.torch.DistributedNeighborAllreduceOptimizer(optimizer, model, num_steps_per_communication=1)¶ An distributed optimizer that wraps another torch.optim.Optimizer through neighbor_allreduce ops over parameters.
Warning
This API will be deprecated in the future. Use
DistributedAdaptWithCombineOptimizerinstead.
-
bluefog.torch.DistributedHierarchicalNeighborAllreduceOptimizer(optimizer, model, num_steps_per_communication=1)¶ An distributed optimizer that wraps another torch.optim.Optimizer through hierarchical_neighbor_allreduce ops over parameters.
Warning
This API will be deprecated in the future. Use
DistributedAdaptWithCombineOptimizerinstead.
-
bluefog.torch.init(topology_fn: Optional[Callable[[int], networkx.classes.digraph.DiGraph]] = None, is_weighted: bool = False)¶ A function that initializes BlueFog.
- Parameters
topology_fn – A callable function that takes size as input and return networkx.DiGraph object to decide the topology. If not provided a default exponential graph (base 2) structure is called.
is_weighted – If set to true, the neighbor ops like (win_update, neighbor_allreduce) will execute the weighted average instead, where the weight is the value used in topology matrix (including self).
-
bluefog.torch.shutdown() → None¶ A function that shuts BlueFog down.
-
bluefog.torch.size() → int¶ A function that returns the number of BlueFog processes.
- Returns
An integer scalar containing the number of BlueFog processes.
-
bluefog.torch.local_size() → int¶ A function that returns the number of BlueFog processes within the node the current process is running on.
- Returns
An integer scalar containing the number of local BlueFog processes.
-
bluefog.torch.rank() → int¶ A function that returns the BlueFog rank of the calling process.
- Returns
An integer scalar with the BlueFog rank of the calling process.
-
bluefog.torch.local_rank() → int¶ A function that returns the local BlueFog rank of the calling process, within the node that it is running on. For example, if there are seven processes running on a node, their local ranks will be zero through six, inclusive.
- Returns
An integer scalar with the local BlueFog rank of the calling process.
-
bluefog.torch.machine_size() → int¶ A function that returns the BlueFog size of the machine.
- Returns
An integer scalar with the BlueFog size of the machine.
-
bluefog.torch.machine_rank() → int¶ A function that returns the BlueFog rank of the machine.
- Returns
An integer scalar with the BlueFog rank of the machine.
-
bluefog.torch.load_topology() → networkx.classes.digraph.DiGraph¶ A funnction that returns the virtual topology MPI used.
- Returns
networkx.DiGraph.
- Return type
topology
-
bluefog.torch.set_topology(topology: Optional[networkx.classes.digraph.DiGraph] = None, is_weighted: bool = False) → bool¶ A function that sets the virtual topology MPI used.
- Parameters
Topo – A networkx.DiGraph object to decide the topology. If not provided a default exponential graph (base 2) structure is used.
is_weighted – If set to true, the win_update and neighbor_allreduce will execute the weighted average instead, where the weights are the value used in topology matrix (including self weight). Note win_get/win_put/win_accumulate do not use this weight since win_update already uses these weights.
- Returns
A boolean value that whether topology is set correctly or not.
Example
>>> import bluefog.torch as bf >>> from bluefog.common import topology_util >>> bf.init() >>> bf.set_topology(topology_util.RingGraph(bf.size()))
-
bluefog.torch.load_machine_topology() → networkx.classes.digraph.DiGraph¶ A function that returns the virtual topology for the machine.
- Returns
networkx.DiGraph.
- Return type
machine_topology
-
bluefog.torch.set_machine_topology(topology: Optional[networkx.classes.digraph.DiGraph], is_weighted: bool = False) → bool¶ A function that sets the virtual machine topology.
- Parameters
Topo – A networkx.DiGraph object to decide the machine topology. It shall not be None.
is_weighted – If set to true, hierarchical_neighbor_allreduce will execute the weighted average instead, where the weights are the value used in machine topology matrix (including self weight).
- Returns
A boolean value that whether machine topology is set correctly or not.
Example
>>> import bluefog.torch as bf >>> from bluefog.common import topology_util >>> bf.init() >>> bf.set_machine_topology(topology_util.RingGraph(bf.machine_size()))
-
bluefog.torch.in_neighbor_ranks() → List[int]¶ Return the ranks of all in-neighbors. Notice: No matter self-loop is presented or not, self rank will not be included.
- Returns
in_neighbor_ranks
-
bluefog.torch.out_neighbor_ranks() → List[int]¶ Return the ranks of all out-neighbors. Notice: No matter self-loop is presented or not, self rank will not be included.
- Returns
out_neighbor_ranks
-
bluefog.torch.in_neighbor_machine_ranks() → List[int]¶ Return the machine ranks of all in-neighbors. Notice: No matter self-loop is presented or not, self machine rank will not be included.
- Returns
in_neighbor_machine_ranks
-
bluefog.torch.out_neighbor_machine_ranks() → List[int]¶ Return the machine ranks of all out-neighbors. Notice: No matter self-loop is presented or not, self machine rank will not be included.
- Returns
out_neighbor_machine_ranks
-
bluefog.torch.mpi_threads_supported() → bool¶ A function that returns a flag indicating whether MPI multi-threading is supported.
If MPI multi-threading is supported, users may mix and match BlueFog usage with other MPI libraries, such as mpi4py.
- Returns
A boolean value indicating whether MPI multi-threading is supported.
-
bluefog.torch.unified_mpi_window_model_supported() → bool¶ Returns a boolean value to indicate the MPI_Win model is unified or not. Unfornuately, it is a collective call. We have to create a fake win to get this information.
-
bluefog.torch.nccl_built() → bool¶ Returns True if BlueFog was compiled with NCCL support.
- Returns
A boolean value indicating whether NCCL support was compiled.
-
bluefog.torch.is_homogeneous() → bool¶ Returns True if the cluster is homogeneous.
- Returns
A boolean value indicating whether every node in the cluster has same number of ranks and if it is true it also indicates the ranks are continuous in machines.
-
bluefog.torch.suspend()¶ Suspend the background thread of BlueFog.
It should be used under interactive python environment only.
-
bluefog.torch.resume()¶ Resume the background thread of BlueFog.
It should be used under interactive python environment only.
-
bluefog.torch.allreduce(tensor: torch.Tensor, average: bool = True, is_hierarchical_local=False, name: Optional[str] = None) → torch.Tensor¶ A function that performs averaging or summation of the input tensor over all the Bluefog processes. The input tensor is not modified.
The reduction operation is keyed by the name. If name is not provided, an incremented auto-generated name is used. The tensor type and shape must be the same on all Bluefog processes for a given name. The reduction will not start until all processes are ready to send and receive the tensor.
- Parameters
tensor – A tensor to average and sum.
average – A flag indicating whether to compute average or summation, defaults to average.
is_hierarchical_local – If set, allreduce is executed within one machine instead of global allreduce.
name – A name of the reduction operation.
- Returns
A tensor of the same shape and type as tensor, averaged or summed across all processes.
-
bluefog.torch.allreduce_nonblocking(tensor: torch.Tensor, average: bool = True, is_hierarchical_local=False, name: Optional[str] = None) → int¶ A function that performs nonblocking averaging or summation of the input tensor over all the Bluefog processes. The input tensor is not modified.
The reduction operation is keyed by the name. If name is not provided, an incremented auto-generated name is used. The tensor type and shape must be the same on all Bluefog processes for a given name. The reduction will not start until all processes are ready to send and receive the tensor.
- Parameters
tensor – A tensor to average and sum.
average – A flag indicating whether to compute average or summation, defaults to average.
is_hierarchical_local – If set, allreduce is executed within one machine instead of global allreduce.
name – A name of the reduction operation.
- Returns
A handle to the allreduce operation that can be used with poll() or synchronize().
-
bluefog.torch.allreduce_(tensor: torch.Tensor, average: bool = True, is_hierarchical_local=False, name: Optional[str] = None) → torch.Tensor¶ A function that performs averaging or summation of the input tensor over all the Bluefog processes. The operation is performed in-place.
The reduction operation is keyed by the name. If name is not provided, an incremented auto-generated name is used. The tensor type and shape must be the same on all Bluefog processes for a given name. The reduction will not start until all processes are ready to send and receive the tensor.
- Parameters
tensor – A tensor to average and sum.
average – A flag indicating whether to compute average or summation, defaults to average.
is_hierarchical_local – If set, allreduce is executed within one machine instead of global allreduce.
name – A name of the reduction operation.
- Returns
A tensor of the same shape and type as tensor, averaged or summed across all processes.
-
bluefog.torch.allreduce_nonblocking_(tensor: torch.Tensor, average: bool = True, is_hierarchical_local=False, name: Optional[str] = None) → int¶ A function that performs nonblocking averaging or summation of the input tensor over all the Bluefog processes. The operation is performed in-place.
The reduction operation is keyed by the name. If name is not provided, an incremented auto-generated name is used. The tensor type and shape must be the same on all Bluefog processes for a given name. The reduction will not start until all processes are ready to send and receive the tensor.
- Parameters
tensor – A tensor to average and sum.
average – A flag indicating whether to compute average or summation, defaults to average.
is_hierarchical_local – If set, allreduce is executed within one machine instead of global allreduce.
name – A name of the reduction operation.
- Returns
A handle to the allreduce operation that can be used with poll() or synchronize().
-
bluefog.torch.allgather(tensor: torch.Tensor, name: Optional[str] = None) → torch.Tensor¶ A function that concatenates the input tensor with the same input tensor on all other Bluefog processes. The input tensor is not modified.
The concatenation is done on the first dimension, so the input tensors on the different processes must have the same rank and shape.
- Parameters
tensor – A tensor to allgather.
name – A name of the allgather operation.
- Returns
A tensor of the same type as tensor, concatenated on dimension zero across all processes. The shape is identical to the input shape, except for the first dimension, which may be greater and is the sum of all first dimensions of the tensors in different Bluefog processes.
-
bluefog.torch.allgather_nonblocking(tensor: torch.Tensor, name: Optional[str] = None) → int¶ A function that nonblockingly concatenates the input tensor with the same input tensor on all other Bluefog processes. The input tensor is not modified.
The concatenation is done on the first dimension, so the input tensors on the different processes must have the same rank and shape.
- Parameters
tensor – A tensor to allgather.
name – A name of the allgather operation.
- Returns
A handle to the allgather operation that can be used with poll() or synchronize().
-
bluefog.torch.broadcast(tensor: torch.Tensor, root_rank: int, name: Optional[str] = None) → torch.Tensor¶ A function that broadcasts the input tensor on root rank to the same input tensor on all other Bluefog processes. The input tensor is not modified.
The broadcast operation is keyed by the name. If name is not provided, an incremented auto-generated name is used. The tensor type and shape must be the same on all Bluefog processes for a given name. The broadcast will not start until all processes are ready to send and receive the tensor.
This acts as a thin wrapper around an autograd function. If your input tensor requires gradients, then callings this function will allow gradients to be computed and backpropagated.
- Parameters
tensor – A tensor to broadcast.
root_rank – The rank to broadcast the value from.
name – A name of the broadcast operation.
- Returns
A tensor of the same shape and type as tensor, with the value broadcasted from root rank.
-
bluefog.torch.broadcast_nonblocking(tensor: torch.Tensor, root_rank: int, name: Optional[str] = None) → int¶ A function that nonblockingly broadcasts the input tensor on root rank to the same input tensor on all other Bluefog processes. The input tensor is not modified.
The broadcast operation is keyed by the name. If name is not provided, an incremented auto-generated name is used. The tensor type and shape must be the same on all Bluefog processes for a given name. The broadcast will not start until all processes are ready to send and receive the tensor.
- Parameters
tensor – A tensor to broadcast.
root_rank – The rank to broadcast the value from.
name – A name of the broadcast operation.
- Returns
A handle to the broadcast operation that can be used with poll() or synchronize().
-
bluefog.torch.broadcast_(tensor, root_rank, name=None) → torch.Tensor¶ A function that broadcasts the input tensor on root rank to the same input tensor on all other Bluefog processes. The operation is performed in-place.
The broadcast operation is keyed by the name. If name is not provided, an incremented auto-generated name is used. The tensor type and shape must be the same on all Bluefog processes for a given name. The broadcast will not start until all processes are ready to send and receive the tensor.
- Parameters
tensor – A tensor to broadcast.
root_rank – The rank to broadcast the value from.
name – A name of the broadcast operation.
- Returns
A tensor of the same shape and type as tensor, with the value broadcasted from root rank.
-
bluefog.torch.broadcast_nonblocking_(tensor, root_rank, name=None) → int¶ A function that nonblockingly broadcasts the input tensor on root rank to the same input tensor on all other Bluefog processes. The operation is performed in-place.
The broadcast operation is keyed by the name. If name is not provided, an incremented auto-generated name is used. The tensor type and shape must be the same on all Bluefog processes for a given name. The broadcast will not start until all processes are ready to send and receive the tensor.
- Parameters
tensor – A tensor to broadcast.
root_rank – The rank to broadcast the value from.
name – A name of the broadcast operation.
- Returns
A handle to the broadcast operation that can be used with poll() or synchronize().
-
bluefog.torch.neighbor_allgather(tensor: torch.Tensor, *, src_ranks: Optional[List] = None, dst_ranks: Optional[List] = None, enable_topo_check: bool = True, name: Optional[str] = None) → torch.Tensor¶ A function that concatenates the input tensor with the same input tensor on on all neighbor Bluefog processes (Not include self). The input tensor is not modified.
The concatenation is done on the first dimension, so the input tensors on the different processes must have the same shape except the first dimension. For example: rank 0 with tensor shape [3, 5, 4] and rank 1 with tensor shape [5, 5, 4] are allowed, the output will be [8, 5, 4] assuming two are connected.
If src_ranks and dst_ranks are not provided, the neighbor_allgather gathers the tensors according to the global default topology, which can be obtained through bf.in_neighbor_ranks. Otherwise, the order is the same as src_ranks provided.
- Parameters
tensor – A tensor to allgather.
dst_ranks – A list of destination ranks. If present, ignoring global topology setting. This argument is useful under dynamic topology case. Note dst_ranks and src_ranks should be presented at same time and compatible.
src_ranks – A list of source ranks.
enable_topo_check – When send_neighbors is present, enabling this option checks if the sending and recieving neighbors match with each other. Disabling this check can boost the performance.
name – A name of the allgather operation.
- Returns
A tensor of the same type as tensor, concatenated on dimension zero. The shape is identical to the input shape, except for the first dimension. The order of gathered tensors is guaranteed to be the same order as the src_ranks if specified or in_neighbor_ranks through the default topology.
-
bluefog.torch.neighbor_allgather_nonblocking(tensor: torch.Tensor, *, src_ranks: Optional[List] = None, dst_ranks: Optional[List] = None, enable_topo_check: bool = True, name: Optional[str] = None) → int¶ A function that nonblockingly concatenates the input tensor with the same input tensor on all neighbor Bluefog processes (Not include self). The input tensor is not modified.
The concatenation is done on the first dimension, so the input tensors on the different processes must have the same shape except the first dimension. For example: rank 0 with tensor shape [3, 5, 4] and rank 1 with tensor shape [5, 5, 4] are allowed, the output will be [8, 5, 4] assuming two are connected.
If src_ranks and dst_ranks is not provided, the neighbor_allgather gather the tensors according to the global default topology.
- Parameters
tensor – A tensor to allgather.
src_ranks – A list of source ranks. If present, ignoring global topology setting. This argument is useful under dynamic topology case. Note dst_ranks and src_ranks should be presented at same time and compatible.
dst_ranks – A list of destination ranks.
enable_topo_check – When send_neighbors is present, enabling this option checks if the sending and recieving neighbors match with each other. Disabling this check can boost the performance.
name – A name of the allgather operation.
- Returns
A handle to the neighbor_allgather operation that can be used with poll() or synchronize(). Check neighbor_allgather function for the output tensor information.
-
bluefog.torch.neighbor_allreduce(tensor: torch.Tensor, *, self_weight: Optional[float] = None, src_weights: Optional[Dict[int, float]] = None, dst_weights: Optional[Union[Dict[int, float], List[int]]] = None, enable_topo_check: bool = True, name: Optional[str] = None) → torch.Tensor¶ A function that performs weighted averaging of the input tensor over the negihbors and itself in the Bluefog processes. The default behavior is (uniformly) average.
The input tensor is not modified.
The reduction operation is keyed by the name. If name is not provided, an incremented auto-generated name is used. The tensor type and shape must be the same on all Bluefog processes for a given name. The reduction will not start until all processes are ready to send and receive the tensor.
- Parameters
tensor – A tensor to execute weighted average with neighbors.
self_weight – The weight for self node, used with neighbor_weights.
src_weights – The weights for in-neighbor nodes, used with self weight. If neighbor_weights is presented, the return tensor will return the weighted average defined by these weights and the self_weight. If not, the return tensor will return the weighted average defined by the topology weights is provided or uniformly average. The data structure of weights should be {rank : weight} and rank has to belong to the (in-)neighbors.
dst_weights – The weights for out-neighbor nodes. If set to be None, assume the the current node sends to all of its (out-)neighbors. If having values, assume only part of (out-)neighbors will be sent to. If set to be a list, assume all the weights are one. In this mode, this node sends its value to partial neighbors listed in this variable in a dynamic graph, and self_weight and src_weights must be present.
enable_topo_check – When send_neighbors is present, enabling this option checks if the sending and recieving neighbors match with each other. Disabling this check can boost the performance.
name – A name of the reduction operation.
- Returns
A tensor of the same shape and type as tensor, across all processes.
Note: self_weight and neighbor_weights must be presented at the same time.
-
bluefog.torch.neighbor_allreduce_nonblocking(tensor: torch.Tensor, *, self_weight: Optional[float] = None, src_weights: Optional[Dict[int, float]] = None, dst_weights: Optional[Union[Dict[int, float], List[int]]] = None, enable_topo_check: bool = True, name: Optional[str] = None) → int¶ A function that nonblockingly performs weighted averaging of the input tensor over the negihbors and itself in the Bluefog processes. The default behavior is (uniformly) average.
The input tensor is not modified.
The reduction operation is keyed by the name. If name is not provided, an incremented auto-generated name is used. The tensor type and shape must be the same on all Bluefog processes for a given name. The reduction will not start until all processes are ready to send and receive the tensor.
- Parameters
tensor – A tensor to execute weighted average with neighbors.
self_weight – The weight for self node, used with neighbor_weights.
src_weights – The weights for in-neighbor nodes, used with self weight. If neighbor_weights is presented, the return tensor will return the weighted average defined by these weights and the self_weight. If not, the return tensor will return the weighted average defined by the topology weights is provided or uniformly average. The data structure of weights should be {rank : weight} and rank has to belong to the (in-)neighbors.
dst_weights – The weights for out-neighbor nodes. If set to be None, assume the the current node sends to all of its (out-)neighbors. If having values, assume only part of (out-)neighbors will be sent to. If set to be a list, assume all the weights are one. In this mode, this node sends its value to partial neighbors listed in this variable in a dynamic graph, and self_weight and src_weights must be present.
enable_topo_check – When send_neighbors is present, enabling this option checks if the sending and recieving neighbors match with each other. Disabling this check can boost the performance.
name – A name of the neighbor_allreduce operation.
- Returns
A handle to the neighbor_allreduce operation that can be used with poll() or synchronize().
Note: self_weight and neighbor_weights must be presented at the same time.
-
bluefog.torch.hierarchical_neighbor_allreduce(tensor: torch.Tensor, self_weight: Optional[float] = None, neighbor_machine_weights: Optional[Dict[int, float]] = None, send_neighbor_machines: Optional[List[int]] = None, enable_topo_check: bool = False, name: Optional[str] = None) → torch.Tensor¶ A function that performs weighted averaging of the input tensor over the negihbor machines and itself in the Bluefog processes. It is similar to neighbor_allreduce. But each machine runs allreduce internal first to form a super node then executes the neighbor allreduce at machine level. The default behavior is (uniformly) average.
The input tensor is not modified.
The reduction operation is keyed by the name. If name is not provided, an incremented auto-generated name is used. The tensor type and shape must be the same on all Bluefog processes for a given name. The reduction will not start until all processes are ready to send and receive the tensor.
Warning: This function should be called only under homogenerous environment, all machines have same number of Bluefog processes – bf.local_size().
- Parameters
tensor – A tensor to execute weighted average with neighbor machines.
self_weight – The weight for self node, used with neighbor_weights.
neighbor_machine_weights – The weights for in-neighbor nodes, used with self weight. The data structure of weights should be {machine id : weight}. All processes under same machine should specifiy the same weights dictionary.
send_neighbor_machines – The list of neighbor machines to be sent to. All processes under same machine should specifiy the same machine id.
enable_topo_check – When send_neighbors is present, enabling this option checks if the sending and recieving neighbors match with each other. Disabling this check can boost the performance.
name – A name of the reduction operation.
- Returns
A tensor of the same shape and type as tensor, across all processes.
-
bluefog.torch.hierarchical_neighbor_allreduce_nonblocking(tensor: torch.Tensor, self_weight: Optional[float] = None, neighbor_machine_weights: Optional[Dict[int, float]] = None, send_neighbor_machines: Optional[List[int]] = None, enable_topo_check: bool = False, name: Optional[str] = None) → int¶ A function that nonblockingly performs weighted averaging of the input tensor over the negihbor machines and itself in the Bluefog processes. It is similar to neighbor_allreduce. But each machine runs allreduce internal first to form a super node then executes the neighbor allreduce at machine level. The default behavior is (uniformly) average.
The input tensor is not modified.
The reduction operation is keyed by the name. If name is not provided, an incremented auto-generated name is used. The tensor type and shape must be the same on all Bluefog processes for a given name. The reduction will not start until all processes are ready to send and receive the tensor.
Warning: This function should be called only under homogenerous environment, all machines have same number of Bluefog processes – bf.local_size().
- Parameters
tensor – A tensor to execute weighted average with neighbor machines.
self_weight – The weight for self node, used with neighbor_weights.
neighbor_machine_weights – The weights for in-neighbor nodes, used with self weight. The data structure of weights should be {machine id : weight}. All processes under same machine should specifiy the same weights dictionary.
send_neighbor_machines – The list of neighbor machines to be sent to. All processes under same machine should specifiy the same machine id.
enable_topo_check – When send_neighbors is present, enabling this option checks if the sending and recieving neighbors match with each other. Disabling this check can boost the performance.
name – A name of the reduction operation.
- Returns
A handle to the hierarchical_neighbor_allreduce operation that can be used with poll() or synchronize().
-
bluefog.torch.poll(handle: int) → bool¶ Polls an allreduce, neighbor_allreduce, etc operation handle to determine whether underlying nonblocking operation has completed. After poll() returns True, wait() will return without blocking.
- Parameters
handle – A handle returned by an allreduce, neighbor_allreduce, etc. nonblocking operation.
- Returns
A flag indicating whether the operation has completed.
-
bluefog.torch.synchronize(handle: int) → torch.Tensor¶ Wait an allreduce, neighbor_allreduce, etc operation until it’s completed. Returns the result of the operation. It is the same function as wait().
- Parameters
handle – A handle returned by an allreduce, neighbor_allreduce, etc. nonblocking operation.
- Returns
An output tensor of the operation.
- Return type
torch.Tensor
-
bluefog.torch.wait(handle: int) → torch.Tensor¶ Wait an allreduce, neighbor_allreduce, etc operation until it’s completed. Returns the result of the operation. It is just alias of synchronize() function.
- Parameters
handle – A handle returned by an allreduce, neighbor_allreduce, etc. nonblocking operation.
- Returns
An output tensor of the operation.
- Return type
torch.Tensor
-
bluefog.torch.barrier()¶ Barrier function to sychronize all MPI processes.
After this function returns, it is guaranteed that all blocking functions before it is finished.
-
bluefog.torch.win_create(tensor: torch.Tensor, name: str, zero_init: bool = False) → bool¶ Create MPI window for remote memoery access.
The window is dedicated to the provided tensor only, which is identified by unqiue name. It is a blocking operation, which required all bluefog process involved. The initial values of MPI windows for neighbors are the same as input tensor unless zero_init is set to be true.
- Parameters
tensor (torch.Tensor) – Provide the size, data type, and/or memory for window.
name (str) – The unique name to associate the window object.
zero_init (boll) – If set true, the buffer value initialize as zero instead of the value of tensor.
- Returns
Indicate the creation succeed or not.
- Return type
bool
Note: The window with same name across different bluefog processes should associate the tensor with same shape. Otherwise, the rest win_ops like win_update, win_put may encounter unrecoverable memory segmentation fault.
-
bluefog.torch.win_free(name: Optional[str] = None) → bool¶ Free the MPI windows associated with name.
- Parameters
name (str) – The unique name to associate the window object. If name is none, free all the window objects.
- Returns
Indicate the free succeed or not.
- Return type
bool
-
bluefog.torch.win_update(name: str, self_weight: Optional[float] = None, neighbor_weights: Optional[Dict[int, float]] = None, reset: bool = False, clone: bool = False, require_mutex: bool = False) → torch.Tensor¶ Locally synchronized the window objects and returned the reduced neighbor tensor. Note the returned tensor is the same tensor used in win_create and in-place modification is happened. During the update, a mutex for local variable is acquired.
- Parameters
name – The unique name to associate the window object.
self_weight – the weight for self node, used with neighbor_weights.
neighbor_weights – the weights for neighbor nodes, used with self_weight. If neighbor_weights is presented, the return tensor will return the weighted average defined by these weights and the self_weight. If not, the return tensor will return the weighted average defined by the topology weights if provided or mean value. The data structure of weights should be {rank : weight} and rank has to belong to the (in-)neighbors.
reset – If reset is True, the buffer used to store the neighbor tensor included in neighbor_weights will be reset to zero. The reset is always happened after the weights computation. If neighbor_weights is not presented and reset is True, all the neighbor will be reset.
clone – If set up to be true, the win_update result will return a new tensor instead of in-place change.
require_mutex – If set to be true, the window mutex associated with local process will be acquired.
- Returns
The average tensor of all neighbors’ cooresponding tensors.
- Return type
torch.Tensor
Note: Weights here will be useful if you need a dynamic weighted average, i.e. the weights change with the iterations. If static weight need, then setting the weights through the bf.set_topology(.., is_weighted=True) is a better choice.
Note2: self_weight and neighbor_weights must be presented at the same time.
-
bluefog.torch.win_update_then_collect(name: str, require_mutex: bool = True) → torch.Tensor¶ A utility function to sync the neighbor buffers then accumulate all neighbor buffers’ tensors into self tensor and clear the buffer. It is equivalent to
>>> win_update(name, self_weight=1.0, neighbor_weights={neighbor: 1.0}, reset=True, require_mutex=require_mutex)
- Parameters
name – The unique name to associate the window object.
- Returns
The average tensor of all neighbors’ cooresponding tensors.
- Return type
torch.Tensor
-
bluefog.torch.win_put_nonblocking(tensor: torch.Tensor, name: str, self_weight: Optional[float] = None, dst_weights: Optional[Dict[int, float]] = None, require_mutex: bool = False) → int¶ Passively put the tensor into neighbor’s shared window memory. This is a non-blocking function, which will return without waiting the win_put operation is really finished.
- Parameters
tesnor – The tensor that shares to neighbor.
name – The unique name to associate the window object.
self_weight – In-place multiply the weight to tensor (Happened after win_put send tensor information to neigbors), Default is 1.0.
dst_weights – A dictionary that maps the destination ranks to the weight. Namely, {rank: weight} means put tensor * weight to the rank neighbor. If not provided, dst_weights will be set as all neighbor ranks defined by virtual topology with weight 1. Note dst_weights should only contain the ranks that belong to out-neighbors.
require_mutex – If set to be true, out-neighbor process’s window mutex will be acquired.
- Returns
A handle to the win_put operation that can be used with win_poll() or win_wait().
-
bluefog.torch.win_put(tensor: torch.Tensor, name: str, self_weight: Optional[float] = None, dst_weights: Optional[Dict[int, float]] = None, require_mutex: bool = False) → bool¶ Passively put the tensor into neighbor’s shared window memory. This is a blocking function, which will return until win_put operation is finished.
- Parameters
tensor – The tensor that shares to neighbor.
name – The unique name to associate the window object.
self_weight – In-place multiply the weight to tensor (Happened after win_put send tensor information to neigbors), Default is 1.0.
dst_weights – A dictionary that maps the destination ranks to the weight. Namely, {rank: weight} means put tensor * weight to the rank neighbor. If not provided, dst_weights will be set as all neighbor ranks defined by virtual topology with weight 1. Note dst_weights should only contain the ranks that belong to out-neighbors.
require_mutex – If set to be true, out-neighbor process’s window mutex will be acquired.
- Returns
A bool value to indicate the put succeeded or not.
-
bluefog.torch.win_get_nonblocking(name: str, src_weights: Optional[Dict[int, float]] = None, require_mutex: bool = False) → int¶ Passively get the tensor(s) from neighbors’ shared window memory into local shared memory, which cannot be accessed in python directly. The win_update function is responsible for fetching that memeory. This is a non-blocking function, which will return without waiting the win_get operation is really finished.
- Parameters
name – The unique name to associate the window object.
src_weights – A dictionary that maps the source ranks to the weight. Namely, {rank: weight} means get tensor from rank neighbor multipling the weight. If not provided, src_weights will be set as all neighbor ranks defined by virtual topology with weight 1.0. Note src_weights should only contain the in-neighbors only.
require_mutex – If set to be true, out-neighbor process’s window mutex will be acquired.
- Returns
A handle to the win_get operation that can be used with win_poll() or win_wait().
-
bluefog.torch.win_get(name: str, src_weights: Optional[Dict[int, float]] = None, require_mutex: bool = False) → bool¶ Passively get the tensor(s) from neighbors’ shared window memory into local shared memory, which cannot be accessed in python directly. The win_update function is responsible for fetching that memeory. This is a blocking function, which will return until win_get operation is finished.
- Parameters
tensor – A tensor to get the result, should have same shape and type of the window object associated with name.
name – The unique name to associate the window object.
src_weights – A dictionary that maps the source ranks to the weight. Namely, {rank: weight} means get tensor * weight to the rank neighbor. If not provided, src_weights will be set as all neighbor ranks defined by virtual topology with weight 1.0 / (neighbor_size+1). Note src_weights should only contain the ranks that either belong to int-neighbors or self.
require_mutex – If set to be true, out-neighbor process’s window mutex will be acquired.
- Returns
A bool value to indicate the get succeeded or not.
-
bluefog.torch.win_accumulate_nonblocking(tensor: torch.Tensor, name: str, self_weight: Optional[float] = None, dst_weights: Optional[Dict[int, float]] = None, require_mutex: bool = False) → bool¶ Passively accmulate the tensor into neighbor’s shared window memory. Only SUM ops is supported now. This is a non-blocking function, which will return without waiting the win_accumulate operation is really finished.
- Parameters
tesnor – The tensor that shares to neighbor.
name – The unique name to associate the window object.
self_weight – In-place multiply the weight to tensor (Happened after win_accumulate send tensor information to neigbors), Default is 1.0.
dst_weights – A dictionary that maps the destination ranks to the weight. Namely, {rank: weight} means accumulate tensor * weight to the rank neighbor. If not provided, dst_weights will be set as all neighbor ranks defined by virtual topology with weight 1. Note dst_weights should only contain the ranks that belong to out-neighbors.
require_mutex – If set to be true, out-neighbor process’s window mutex will be acquired.
- Returns
A handle to the win_accmulate operation that can be used with win_poll() or win_wait().
-
bluefog.torch.win_accumulate(tensor: torch.Tensor, name: str, self_weight: Optional[float] = None, dst_weights: Optional[Dict[int, float]] = None, require_mutex: bool = False) → bool¶ Passively accmulate the tensor into neighbor’s shared window memory. Only SUM ops is supported now. This is a blocking function, which will return until win_accumulate operation is finished.
- Parameters
tesnor – The tensor that shares to neighbor.
name – The unique name to associate the window object.
self_weight – In-place multiply the weight to tensor (Happened after win_accumulate send tensor information to neigbors), Default is 1.0.
dst_weights – A dictionary that maps the destination ranks to the weight. Namely, {rank: weight} means accumulate tensor * weight to the rank neighbor. If not provided, dst_weights will be set as all neighbor ranks defined by virtual topology with weight 1. Note dst_weights should only contain the ranks that belong to out-neighbors.
require_mutex – If set to be true, out-neighbor process’s window mutex will be acquired.
- Returns
A bool value to indicate the accumulate succeeded or not.
-
bluefog.torch.win_wait(handle: int) → bool¶ Wait until the async win ops identified by handle is done.
-
bluefog.torch.win_poll(handle: int) → bool¶ Return whether the win ops identified by handle is done or not.
-
bluefog.torch.win_mutex(name: str, for_self=False, ranks: Optional[List[int]] = None)¶ A win object implemented mutex context manager. Note, there are N distributed mutex over N corresponding processes.
- Parameters
name – Used to get the mutex for the window that registered by name.
ranks – The mutex associated with the specified ranks is acquired. If not presented, the mutex with all out_neighbor ranks are acquired.
for_self – If it is false, it will require the remote mutexes at processes ranks, which is specified by argument ranks). If it is true, it will require the self mutex.
Example
>>> bf.win_create(tensor, name) >>> with win_mutex(name): tensor = bf.win_update_then_collect(name) >>> win_put(tensor, name)
-
bluefog.torch.get_win_version(name: str) → Dict[int, int]¶ Get the version of tensor stored in the win buffer.
- Parameters
name – The unique name to get the associated window object.
- Returns
A dictionary maps from neighbor ranks to version. 0 means the latest tensor stored in win buffer has been read/sync. Non-negative value means the tensor has been updated through put or get before read/sync.
-
bluefog.torch.get_current_created_window_names() → List[str]¶ Return the names of current created windows.
-
bluefog.torch.win_associated_p(name: str) → float¶ Return the associated correction P, used in Push-Sum algorithm, for each named window.
- Parameters
name (str) – The unique name to associate the window object.
- Returns
The p value. (Initialized as 1.)
- Return type
float
-
bluefog.torch.turn_on_win_ops_with_associated_p()¶ Turn on the global state of win operations with associated p.
If it is state is on, all win ops such as put, update, accumulate also apply on the associated p value as well. The default state is off.
-
bluefog.torch.turn_off_win_ops_with_associated_p()¶ Turn off the global state of win operations with associated p.
-
bluefog.torch.set_skip_negotiate_stage(value: bool) → None¶ Skip the negotiate stage or not. (Default state is no skip).
For some MPI implementation, it doesn’t have support for multiple thread. To use the win ops, it has to turn off the negotiate the stage. After turn off the negotiate the sate the error in collective callse like size mismatch, order of tensor is randomized, may not be able to be handled properly. But it may help to boost the performance.
-
bluefog.torch.get_skip_negotiate_stage() → bool¶ Get the value of skip the negotiate stage. (Default state is no skip).
-
bluefog.torch.timeline_start_activity(tensor_name: str, activity_name: str) → bool¶ A python interface to call the timeline for StartActivity. If you want to use this function, please make sure to turn on the timeline first by setting the ENV variable BLUEFOG_TIMELINE = {file_name}, or use bfrun –timeline-filename {file_name} …
- Parameters
tensor_name (str) – The activity associated tensor name.
activity_name (str) – The activity type.
- Returns
A boolean value that whether timeline is executed correctly or not.
Example
>>> import bluefog.torch as bf >>> from bluefog.common.util import env >>> with env(BLUEFOG_TIMELINE="./timeline_file"): >>> bf.init() >>> bf.timeline_start_activity(tensor_name, activity_name) >>> ... >>> bf.timeline_end_activity(tensor_name)
-
bluefog.torch.timeline_end_activity(tensor_name: str) → bool¶ A python interface to call the timeline for EndActivity.
Please check comments in timeline_start_activity for more explanation.
-
bluefog.torch.timeline_context(tensor_name: str, activity_name: str)¶ Context manager for activating timeline record. If you want to use this function, please make sure to turn on the timeline first by setting the ENV variable BLUEFOG_TIMELINE = {file_name}, or use bfrun –timeline-filename {file_name} …
- Parameters
tensor_name (str) – The activity associated tensor name.
activity_name (str) – The activity type.
Example
>>> with bf.timeline_context(tensor_name, activity_name): >>> time.sleep(1.0)
-
bluefog.torch.broadcast_optimizer_state(optimizer, root_rank)¶ Broadcasts an optimizer state from root rank to all other processes.
- Parameters
optimizer – An optimizer.
root_rank – The rank of the process from which the optimizer will be broadcasted to all other processes.
-
bluefog.torch.broadcast_parameters(params, root_rank)¶ Broadcasts the parameters from root rank to all other processes. Typical usage is to broadcast the
model.state_dict(),model.named_parameters(), ormodel.parameters().- Parameters
params – One of the following: - list of parameters to broadcast - dict of parameters to broadcast
root_rank – The rank of the process from which parameters will be broadcasted to all other processes.
-
bluefog.torch.allreduce_parameters(params)¶ Allreduce the parameters of all other processes, i.e., forcing all processes to have same average model. Typical usage is to allreduce the
model.named_parameters(), ormodel.parameters().- Parameters
params – One of the following: - list of parameters to allreduce - dict of parameters to allreduce
-
bluefog.torch.GetRecvWeights(topo: networkx.classes.digraph.DiGraph, rank: int) → Tuple[float, Dict[int, float]]¶ Return a Tuple of self_weight and neighbor_weights for receiving dictionary.
-
bluefog.torch.GetSendWeights(topo: networkx.classes.digraph.DiGraph, rank: int) → Tuple[float, Dict[int, float]]¶ Return a Tuple of self_weight and neighbor_weights for sending dictionary.
-
bluefog.torch.IsRegularGraph(topo: networkx.classes.digraph.DiGraph) → bool¶ Dtermine a graph is regular or not, i.e. all nodes have the same degree.
-
bluefog.torch.IsTopologyEquivalent(topo1: networkx.classes.digraph.DiGraph, topo2: networkx.classes.digraph.DiGraph) → bool¶ Determine two topologies are equivalent or not.
Notice we do not check two topologies are isomorphism. Instead checking the adjacenty matrix is the same only.
-
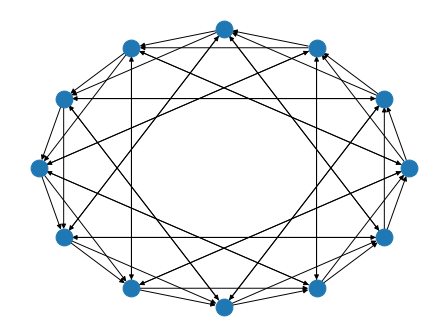
bluefog.torch.ExponentialTwoGraph(size: int) → networkx.classes.digraph.DiGraph¶ Generate graph topology such that each points only connected to a point such that the index difference is the power of 2.
Example: A ExponentialTwoGraph with 12 nodes:
>>> import networkx as nx >>> from bluefog.common import topology_util >>> G = topology_util.ExponentialTwoGraph(12) >>> nx.draw_circular(G)
-
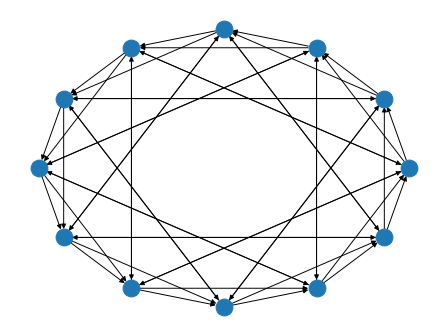
bluefog.torch.ExponentialGraph(size: int, base: int = 2) → networkx.classes.digraph.DiGraph¶ Generate graph topology such that each points only connected to a point such that the index difference is power of base. (Default is 2)
Example: A ExponentialGraph with 12 nodes:
>>> import networkx as nx >>> from bluefog.common import topology_util >>> G = topology_util.ExponentialGraph(12) >>> nx.draw_circular(G)
-
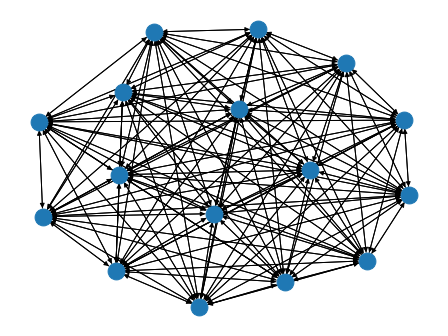
bluefog.torch.FullyConnectedGraph(size: int) → networkx.classes.digraph.DiGraph¶ Generate fully connected structure of graph. For example, a FullyConnectedGraph with 16 nodes:
Example: A FullyConnectedGraph 16 nodes:
>>> import networkx as nx >>> from bluefog.common import topology_util >>> G = topology_util.FullyConnectedGraph(16) >>> nx.draw_spring(G)
-
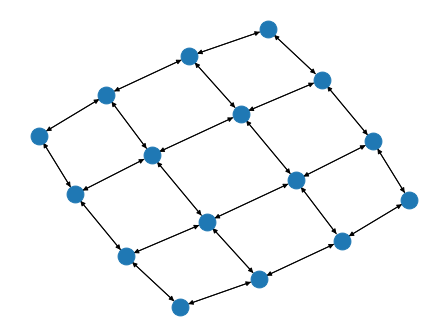
bluefog.torch.MeshGrid2DGraph(size: int, shape: Optional[Tuple[int, int]] = None) → networkx.classes.digraph.DiGraph¶ Generate 2D MeshGrid structure of graph.
Assume shape = (nrow, ncol), when shape is provided, a meshgrid of nrow*ncol will be generated. when shape is not provided, nrow and ncol will be the two closest factors of size.
For example: size = 24, nrow and ncol will be 4 and 6, respectively. We assume nrow will be equal to or smaller than ncol. If size is a prime number, nrow will be 1, and ncol will be size, which degrades the topology into a linear one.
Example: A MeshGrid2DGraph with 16 nodes:
>>> import networkx as nx >>> from bluefog.common import topology_util >>> G = topology_util.MeshGrid2DGraph(16) >>> nx.draw_spring(G)
-
bluefog.torch.RingGraph(size: int, connect_style: int = 0) → networkx.classes.digraph.DiGraph¶ Generate ring structure of graph (uniliteral). Argument connect_style should be an integer between 0 and 2, where 0 represents the bi-connection, 1 represents the left-connection, and 2 represents the right-connection.
Example: A RingGraph with 16 nodes:
>>> import networkx as nx >>> from bluefog.common import topology_util >>> G = topology_util.RingGraph(16) >>> nx.draw_circular(G)
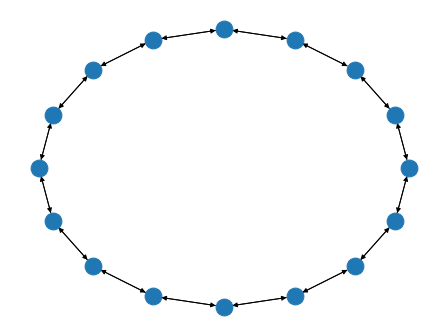
-
bluefog.torch.StarGraph(size: int, center_rank: int = 0) → networkx.classes.digraph.DiGraph¶ Generate star structure of graph.
All other ranks are connected to the center_rank. The connection is bidirection, i.e. if the weight from node i to node j is non-zero, so is the weight from node j to node i.
Example: A StarGraph with 16 nodes:
>>> import networkx as nx >>> from bluefog.common import topology_util >>> G = topology_util.StarGraph(16) >>> nx.draw_spring(G)
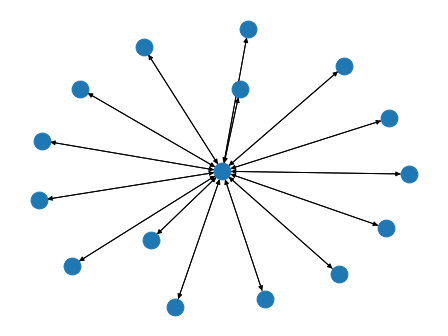
-
bluefog.torch.SymmetricExponentialGraph(size: int, base: int = 4) → networkx.classes.digraph.DiGraph¶ Generate symmeteric graph topology such that for the first half of nodes only connected to a point such that the index difference is power of base (Default is 4) and the connectivity for the second half of nodes just mirrored to the first half.
Example: A SymmetricExponentialGraph with 12 nodes
>>> import networkx as nx >>> from bluefog.common import topology_util >>> G = topology_util.SymmetricExponentialGraph(12) >>> nx.draw_circular(G)
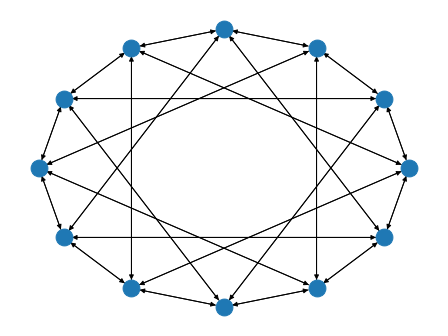
-
bluefog.torch.GetDynamicOnePeerSendRecvRanks(topo: networkx.classes.digraph.DiGraph, self_rank: int) → Iterator[Tuple[List[int], List[int]]]¶ A utility function to generate 1-outoging send rank and corresponding recieving rank(s).
- Parameters
topo (nx.DiGraph) – The base topology to generate dynamic send and receive ranks.
self_rank (int) – The self rank.
- Yields
Iterator[Tuple[List[int], List[int]]] – send_ranks, recv_ranks.
Example
>>> from bluefog.common import topology_util >>> topo = topology_util.PowerTwoRingGraph(10) >>> gen = topology_util.GetDynamicOnePeerSendRecvRanks(topo, 0) >>> for _ in range(10): >>> print(next(gen))
-
bluefog.torch.GetExp2DynamicSendRecvMachineRanks(world_size: int, local_size: int, self_rank: int, local_rank: int) → Iterator[Tuple[List[int], List[int]]]¶ A utility function to generate 1-outgoing send machine id and corresponding recieving machine id(s) for Exponentia-2 topology.
- Parameters
world_size (int) – the size of all nodes; world_size = num_machines * nodes_per_machine
local_size (int) – number of nodes in each machine
self_rank (int) – The self rank.
local_rank (int) – The self local rank.
- Yields
Iterator[Tuple[List[int], List[int]]] – send_machine_ids, recv_machine_ids.
Warning
This function should be used under homogeneous enviroment only, i.e. all machines have the same number of local processes.
-
bluefog.torch.GetInnerOuterRingDynamicSendRecvRanks(world_size: int, local_size: int, self_rank: int) → Iterator[Tuple[List[int], List[int]]]¶ A utility function to generate 1-outgoing send rank and corresponding recieving rank(s) for Inner-Ring-Outer-Ring topology.
- Parameters
world_size (int) – the size of all nodes; world_size = num_machines * nodes_per_machine
local_size (int) – number of nodes in each machine
self_rank (int) – The self rank.
- Yields
Iterator[Tuple[List[int], List[int]]] – send_ranks, recv_ranks.
Example
>>> from bluefog.common import topology_util >>> world_size, local_size = bf.size(), bf.local_size() >>> gen = topology_util.GetInnerOuterRingDynamicSendRecvRanks(world_size, local_size, 0) >>> for _ in range(10): >>> print(next(gen))
-
bluefog.torch.GetInnerOuterExpo2DynamicSendRecvRanks(world_size: int, local_size: int, self_rank: int) → Iterator[Tuple[List[int], List[int]]]¶ A utility function to generate 1-outgoing send rank and corresponding recieving rank(s) for Inner-Exp2-Outer-Exp2 ring topology.
- Parameters
world_size (int) – the size of all nodes; world_size = num_machines * nodes_per_machine
local_size (int) – number of nodes in each machine
self_rank (int) – The self rank.
- Yields
Iterator[Tuple[List[int], List[int]]] – send_ranks, recv_ranks.
Example
>>> from bluefog.common import topology_util >>> world_size, local_size = bf.size(), bf.local_size() >>> gen = topology_util.GetInnerOuterExpo2DynamicSendRecvRanks(world_size, local_size, 0) >>> for _ in range(10): >>> print(next(gen))
-
bluefog.torch.InferSourceFromDestinationRanks(dst_ranks: List[int], construct_adjacency_matrix: bool = False) → Union[List[int], Tuple[List[int], numpy.array]]¶ Infer the source ranks from destination ranks. This is collective communication call.
- Parameters
dst_ranks – A list of destination ranks.
construct_adjacency_matrix – If true, adjacency matrix will be return instead. Element w_{ij} represents the weights sending from node i to node j. We use column normalized style, i.e. the sum of receiving weight is 1.
- Raises
ValueError – If dst_ranks or src_ranks does not contain integer from 0 to size-1.
- Returns
If construct_adjacency_matrix is false, returns the source ranks list. If construct_adjacency_matrix is true, returns the the source ranks list and a 2-D numpy array.
-
bluefog.torch.InferDestinationFromSourceRanks(src_ranks: List[int], construct_adjacency_matrix: bool = False) → Union[List[int], numpy.array]¶ Infer the destination ranks from source ranks. This is collective communication call.
- Parameters
src_ranks – A list of destination ranks.
construct_adjacency_matrix – If true, adjacency matrix will be return instead. Element w_{ij} represents the weights sending from node i to node j. We use column normalized style, i.e. the sum of receiving weight is 1.
- Raises
ValueError – If dst_ranks or src_ranks does not contain integer from 0 to size-1.
- Returns
If construct_adjacency_matrix is false, returns the destination ranks list. If construct_adjacency_matrix is true, returns the the sodestinationrce ranks list and a 2-D numpy array.